BERT là một cột mốc quan trọng trong lĩnh vực NLP. Đây là một mô hình ngôn ngữ rất mạnh giúp cải thiện đáng kể khả năng giải quyết các nhiệm vụ NLP. Bài viết này giới thiệu lý thuyết và sử dụng BERT từ nhiều quan điểm thông qua lý thuyết và trường hợp. Nếu bạn là một học viên NLP, bạn có thể tìm hiểu việc sử dụng BERT theo hướng dẫn trường hợp trong bài viết này.
Nếu bạn đã chú ý đến thông tin về học tập sâu, bạn hẳn đã nghe nói về BERT, một chủ đề rất nóng trong năm qua.
Vào cuối năm 2018, các nhà nghiên cứu tại ngôn ngữ trí tuệ nhân tạo của Google đã mở ra một công nghệ xử lý ngôn ngữ tự nhiên mới (NLP), được gọi là BERT (Đại diện bộ mã hóa hai chiều của Transformers). Đây là một bước đột phá lớn đã phá hủy toàn bộ cộng đồng học tập sâu với hiệu suất đáng kinh ngạc của nó. Trong bài đăng trên blog này, chúng tôi sẽ tìm hiểu và tìm hiểu về BERT bằng cách trả lời 5 câu hỏi sau:
- Tại sao chúng ta cần BERT?
- Ý tưởng cốt lõi đằng sau BERT là gì?
- BERT hoạt động như thế nào?
- Trong trường hợp nào BERT được sử dụng và tinh chỉnh được thực hiện như thế nào?
- Làm thế nào để sử dụng BERT? Hướng dẫn thực hành phân loại văn bản BERT
Bài viết này trước tiên sẽ giải thích lý thuyết về BERT, và sau đó sử dụng các trường hợp thực tế để hiểu sâu hơn về BERT.
1. Tại sao chúng ta cần BERT?
Một trong những thách thức lớn nhất đối với NLP là thiếu dữ liệu đào tạo đầy đủ. Nói chung, có rất nhiều dữ liệu văn bản có sẵn, nhưng nếu chúng ta muốn tạo một bộ dữ liệu dành riêng cho nhiệm vụ, chúng ta cần chia dữ liệu này thành nhiều trường khác nhau. Ngay cả sau khi chúng tôi làm điều này, chúng tôi đã kết thúc với hàng trăm hoặc hàng trăm ngàn mẫu đào tạo được dán nhãn con người. Tuy nhiên, để đạt được kết quả tốt hơn, các mô hình NLP dựa trên học tập sâu đòi hỏi lượng dữ liệu lớn hơn. Chỉ bằng cách đào tạo hàng trăm triệu hoặc thậm chí hàng tỷ dữ liệu chú thích mới có thể đạt được kết quả tốt.
Để giúp lấp đầy khoảng trống về khối lượng dữ liệu này, các nhà nghiên cứu đã phát triển các kỹ thuật để đào tạo các mô hình ngôn ngữ phổ quát sử dụng một lượng lớn văn bản không được quản lý trên web làm nguồn dữ liệu (đây được gọi là đào tạo trước). Các mô hình được đào tạo chung này có thể được tinh chỉnh trên các bộ dữ liệu cụ thể cho nhiệm vụ nhỏ hơn. Ví dụ, khi xử lý các câu hỏi như trả lời câu hỏi và phân tích tình cảm, so với đào tạo trên các bộ dữ liệu cụ thể cho nhiệm vụ nhỏ hơn từ đầu, Phương pháp này có thể cải thiện độ chính xác rất nhiều. BERT là một trong những công nghệ đào tạo trước NLP mới và nó đã gây ra cảm giác trong cộng đồng học tập sâu vì nó cho thấy kết quả chính xác nhất trong các nhiệm vụ NLP khác nhau, chẳng hạn như các câu hỏi và câu trả lời.
Một ưu điểm khác của BERT là nó có thể được tải xuống và sử dụng miễn phí. Chúng tôi có thể sử dụng các mô hình BERT để trích xuất dữ liệu tính năng ngôn ngữ chất lượng cao từ văn bản hoặc chúng tôi có thể điều chỉnh các mô hình này cho một kịch bản nhiệm vụ cụ thể, như phân tích tình cảm hoặc trả lời câu hỏi Và sau đó sử dụng dữ liệu của chúng tôi để đưa ra dự đoán tối ưu.
2. Ý tưởng cốt lõi đằng sau BERT là gì?
Một mô hình ngôn ngữ thực sự có nghĩa là gì? Những vấn đề nào mô hình ngôn ngữ cố gắng giải quyết? Về cơ bản, nhiệm vụ của họ là "điền vào chỗ trống" dựa trên bối cảnh. Ví dụ: ví dụ sau:
"Người phụ nữ đã đi đến cửa hàng và mua một đôi giày _____."
Khi mô hình ngôn ngữ hoàn thành câu này, nó đặt trọng số 20% để sử dụng từ "giỏ hàng" và 80% trọng lượng để sử dụng từ "cặp".
Trước khi BERT xuất hiện, các mô hình ngôn ngữ cần phải hiểu văn bản bằng cách quét các chuỗi văn bản từ trái sang phải hoặc kết hợp chúng từ phải sang trái. Phương pháp một chiều này phù hợp hơn để tạo câu - nó có thể dự đoán từ tiếp theo, thêm từ đó vào chuỗi và sau đó dự đoán từ tiếp theo cho đến khi một câu hoàn chỉnh được hình thành.
Với BERT, bạn có thể tạo mô hình ngôn ngữ được đào tạo hai chiều (đây cũng là cải tiến kỹ thuật chính của nó). So với các mô hình ngôn ngữ một chiều, điều này có nghĩa là bây giờ chúng ta có thể hiểu sâu hơn về bối cảnh và dòng ngôn ngữ.
Thay vì dự đoán tuần tự từ tiếp theo, BERT sử dụng một kỹ thuật mới có tên Masked LM (MLM): nó ngẫu nhiên che dấu các từ trong câu và sau đó cố gắng dự đoán chúng. Mặt nạ có nghĩa là mô hình sẽ nhìn theo hai hướng và nó sử dụng bối cảnh đầy đủ của câu, bao gồm bối cảnh bên trái và bên phải, để dự đoán các từ bị che. Không giống như các mô hình ngôn ngữ trước đó, nó xem xét cả đánh dấu trước và đánh dấu tiếp theo. Các mô hình kết hợp từ trái sang phải và phải sang trái dựa trên LSTM hiện tại thiếu "phần thời gian" này. (Chính xác hơn, BERT là không định hướng.)
Nhưng tại sao cách tiếp cận không định hướng này lại mạnh mẽ như vậy?
Các mô hình ngôn ngữ được đào tạo trước có thể không có ngữ cảnh hoặc dựa trên ngữ cảnh. Các đại diện dựa trên bối cảnh có thể là một chiều hoặc hai chiều. Một mô hình không ngữ cảnh như word2vec tạo ra một đại diện nhúng từ đơn (vectơ số) cho mỗi từ trong từ vựng . Ví dụ: từ "ngân hàng" có cùng đại diện không có ngữ cảnh trong "tài khoản ngân hàng" và "ngân hàng của dòng sông". Nhưng trong một câu, mô hình dựa trên ngữ cảnh tạo ra các biểu diễn dựa trên các từ khác trong câu. Ví dụ: trong câu "Tôi đã truy cập vào tài khoản ngân hàng", mô hình bối cảnh một chiều sẽ đại diện cho "ngân hàng" dựa trên "Tôi đã truy cập" và "tài khoản" sẽ không được xem xét tại thời điểm này. Tuy nhiên, BERT sử dụng bối cảnh trước đó và tiếp theo để đại diện cho "ngân hàng" - "Tôi đã truy cập vào tài khoản trên mạng" - bắt đầu từ dưới cùng của mạng lưới thần kinh sâu, khiến nó trở nên hai chiều sâu.
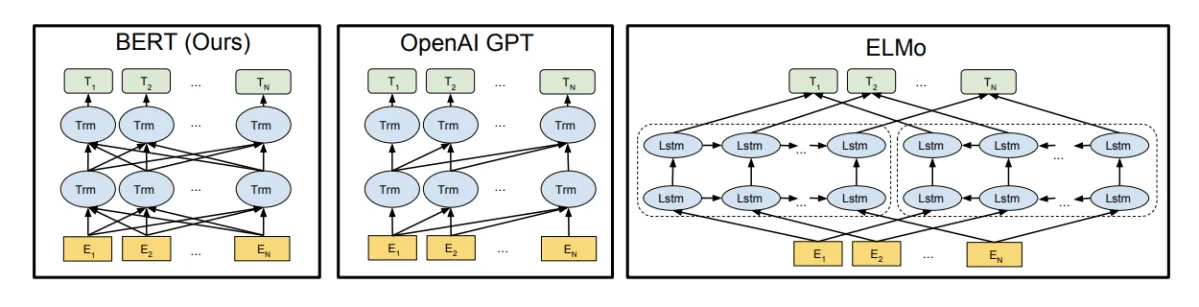
BERT dựa trên kiến trúc mô hình Transformer , không phải LSTM. Các chi tiết về mô hình của BERT sẽ được giới thiệu sau trong bài viết này, nhưng nói chung:
Máy biến áp hoạt động để thực hiện một số bước nhỏ, không đổi. Trong mỗi bước, nó áp dụng một cơ chế ghi nhãn để hiểu mối quan hệ giữa tất cả các từ trong câu, bất kể vị trí của chúng. Ví dụ, đối với câu "Tôi đến ngân hàng sau khi qua sông", bạn cần đảm bảo rằng từ "ngân hàng" chỉ bờ sông, không phải là một tổ chức tài chính. Đạt được mục tiêu của bạn trong một bước.
Ở trên chúng tôi đã giới thiệu các khái niệm chính của BERT, chúng ta hãy xem xét kỹ hơn các chi tiết.
3. BERT hoạt động như thế nào?
BERT được gắn vào "Transformer" (một cơ chế ghi nhãn để tìm hiểu mối quan hệ theo ngữ cảnh giữa các từ trong văn bản). Biến áp cơ bản bao gồm bộ mã hóa để đọc văn bản nhập và bộ giải mã để tạo dự đoán về tác vụ. Vì mục tiêu của BERT là tạo ra một mô hình biểu diễn ngôn ngữ, nên nó chỉ yêu cầu phần mã hóa. Đầu vào của bộ mã hóa BERT là một chuỗi các mã thông báo, lần đầu tiên được chuyển đổi thành một vectơ và sau đó được xử lý trong mạng thần kinh. Nhưng trước khi quá trình xử lý có thể bắt đầu, BERT cần xử lý đầu vào và thêm một số siêu dữ liệu bổ sung:
- Mã thông báo nhúng: Thêm mã thông báo [CLS] vào mã thông báo từ đầu vào ở đầu câu đầu tiên và chèn mã thông báo [SEP] vào cuối mỗi câu.
- Phân đoạn nhúng: Thêm mã thông báo đại diện cho câu A hoặc câu B vào mỗi mã thông báo. Điều này có thể phân biệt bộ mã hóa giữa các câu khác nhau.
- Các nhúng nhúng vị trí: Nhúng vị trí được thêm vào mỗi mã thông báo để chỉ ra vị trí của nó trong câu.
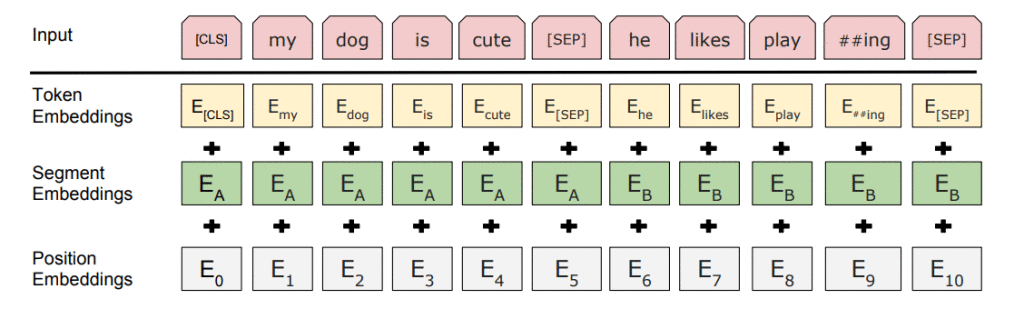
Trong thực tế, Transformer sắp xếp một lớp ánh xạ các chuỗi thành chuỗi, do đó đầu ra cũng là một chuỗi vectơ, với sự tương ứng 1: 1 giữa các thẻ đầu vào và đầu ra ở cùng một chỉ mục. Như chúng ta đã nói trước đây, BERT không cố gắng dự đoán từ tiếp theo trong câu. Đào tạo của nó chủ yếu sử dụng hai chiến lược sau:
1. LM đeo mặt nạ (MLM
Ý tưởng hướng dẫn là "đơn giản": sử dụng mã thông báo (MASK) để che dấu ngẫu nhiên 15% đầu vào từ, sau đó chạy chú thích BERT dựa trên bộ mã hóa, sau đó dự đoán nghĩa của các từ bị che dựa trên các chuỗi từ không được che dấu khác trong ngữ cảnh được cung cấp . Tuy nhiên, phương thức mặt nạ ban đầu này có vấn đề - mô hình chỉ cố gắng dự đoán khi nào mã thông báo [MASK] xuất hiện trong đầu vào và chúng tôi muốn mô hình cố gắng dự đoán mã thông báo chính xác cho dù mã thông báo nào xuất hiện trong đầu vào. Để giải quyết vấn đề này, chúng tôi chọn mã thông báo có mặt nạ 15%:
- Trên thực tế, 80% mã thông báo được thay thế bằng mã thông báo [MASK].
- 10% mã thông báo được thay thế bằng mã thông báo ngẫu nhiên.
- 10% mã thông báo vẫn không thay đổi.
Khi đào tạo chức năng mất BERT, chỉ dự đoán mã thông báo mặt nạ được xem xét và dự đoán của mã thông báo không mặt nạ được bỏ qua. Điều này sẽ khiến mô hình hội tụ chậm hơn nhiều so với mô hình từ trái sang phải hoặc phải sang trái.
2. Dự đoán câu tiếp theo (NSP)
Để hiểu mối quan hệ giữa hai câu, dự đoán câu tiếp theo cũng được sử dụng trong quy trình đào tạo BERT. Các mô hình được đào tạo trước với sự hiểu biết này có thể xử lý các nhiệm vụ liên quan đến Hỏi và Đáp. Trong quá trình đào tạo, mô hình nhận được các cặp câu đầu vào và học cách dự đoán xem câu thứ hai có phải là câu tiếp theo trong văn bản gốc hay không.
Như chúng ta đã thấy trước đó, BERT sử dụng mã thông báo (SEP) đặc biệt để phân tách các câu. Trong quá trình đào tạo, người mẫu nhập hai câu cùng một lúc:
- Có 50% cơ hội là câu thứ hai sau câu đầu tiên.
- Có 50% khả năng đó là một câu ngẫu nhiên từ toàn bộ văn bản.
Sau đó, BERT dự đoán liệu câu thứ hai có ngẫu nhiên hay không và giả sử rằng câu ngẫu nhiên này bị ngắt kết nối với câu đầu tiên:
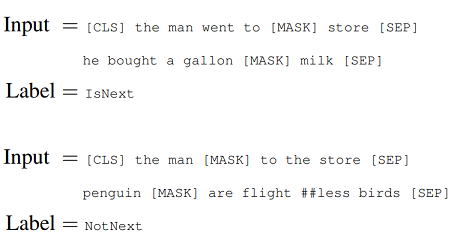
Dự đoán xem câu thứ hai có được kết nối với câu đầu tiên hay không IsNext-Nhãn.
Mô hình được đào tạo bằng cách kết hợp mạng lưới thần kinh Masked LM và dự đoán câu tiếp theo. Điều này là để giảm thiểu chức năng thua lỗ kết hợp của hai chiến lược - cái gọi là "đôi bên cùng có lợi".
Mô hình kiến trúc
Tùy thuộc vào kích thước của kiến trúc mô hình, có bốn phiên bản BERT được đào tạo trước:
BERT-Base: 12 lớp, 768 nút ẩn, 12 đầu chú ý, tham số 110M
BERT-Large: 24 lớp, 1024 nút ẩn, 16 đầu chú ý, tham số 340M
BERT-Base được đào tạo trong 4 ngày trên 4 TPU và BERT-Large được đào tạo trong 4 ngày trên 16 TPU!
Để biết thêm thông tin về siêu âm và nhiều thông tin hơn về kiến trúc và phân tách kết quả, tôi khuyên bạn nên đọc luận án BERT gốc.
4. BERT được sử dụng trong trường hợp nào và tinh chỉnh được thực hiện như thế nào?
BERT vượt trội trong một loạt các kịch bản nhiệm vụ để hiểu ngôn ngữ chung như lý luận ngôn ngữ tự nhiên, phân tích tình cảm, trả lời câu hỏi, phát hiện dịch thuật miễn phí và chấp nhận ngôn ngữ.
Vì vậy, làm thế nào để chúng tôi tinh chỉnh cho các kịch bản nhiệm vụ cụ thể? BERT có thể được sử dụng trong một loạt các nhiệm vụ ngôn ngữ. Nếu chúng ta muốn tinh chỉnh mô hình ban đầu dựa trên tập dữ liệu của riêng mình, chỉ cần thêm một lớp riêng biệt lên trên mô hình lõi.
Ví dụ: giả sử chúng tôi đang tạo một ứng dụng trả lời câu hỏi. Về cơ bản, Q & A chỉ là một nhiệm vụ dự đoán - khi nhận được câu hỏi làm đầu vào, mục tiêu của ứng dụng là xác định câu trả lời đúng từ một số kho văn bản. Do đó, đưa ra một câu hỏi và một đoạn theo ngữ cảnh, mô hình dự đoán các thẻ bắt đầu và kết thúc trong đoạn đó có nhiều khả năng trả lời câu hỏi nhất. Điều này có nghĩa là chúng ta có thể sử dụng mô hình BERT để huấn luyện ứng dụng của mình bằng cách học hai vectơ bổ sung, tương ứng với phần đầu và phần cuối của câu trả lời.

Cũng giống như câu-to-task, câu hỏi trở thành câu đầu tiên trong chuỗi đầu vào và đoạn văn trở thành câu thứ hai. Tuy nhiên, hai tham số mới đã được thêm vào quy trình tinh chỉnh ở đây: vectơ bắt đầu và vectơ kết thúc.
Trong đào tạo tinh chỉnh, các siêu đường kính phù hợp với đào tạo BERT, bài viết này đưa ra hướng dẫn cụ thể về các siêu đường kính cần được điều chỉnh.
Lưu ý rằng nếu chúng tôi muốn thực hiện tinh chỉnh, chúng tôi cần chuyển đổi định dạng đầu vào dữ liệu để đáp ứng các yêu cầu định dạng đặc biệt của mô hình BERT lõi được đào tạo trước. Ví dụ: chúng ta cần thêm các mã thông báo đặc biệt để đánh dấu bắt đầu ((CLS)), câu tách / kết thúc ([SEP]) và ID phân đoạn để đạt được mục đích phân biệt các câu khác nhau và cuối cùng chúng ta có thể chuyển đổi dữ liệu thành các tính năng được sử dụng bởi BERT.
5. Làm thế nào để sử dụng BERT? Hướng dẫn thực hành phân loại văn bản BERT
Từ những điều trên, chúng ta đã học được các khái niệm cơ bản của BERT. Bây giờ chúng ta sẽ xem xét một ví dụ thực tế. Trong hướng dẫn này, tôi sẽ sử dụng bộ dữ liệu đánh giá người dùng Yelp mà bạn có thể tải xuống từ đây . Đây là một nhiệm vụ phân loại văn bản nhị phân đơn giản - mục tiêu là phân chia văn bản ngắn thành các đánh giá tốt và xấu. Đây là quy trình làm việc hoàn chỉnh:
Cài đặt
Thiết lập trong môi trường dòng chảy python tương đối đơn giản:
Sao chép thư viện BERT Github vào máy tính của riêng bạn. Trên thiết bị đầu cuối của bạn, nhập
Code Mã bản sao
b. Tải xuống tệp mô hình BERT được đào tạo trước từ trang BERT Github chính thức . Nó bao gồm các trọng số, siêu âm và các tệp cần thiết khác có chứa thông tin mà BERT đã học trong quá trình đào tạo trước. Lưu nó vào kho lưu trữ git clone của bạn và giải nén nó vào một thư mục. Dưới đây là các liên kết bằng tiếng Anh:
BERT-Base, Uncasing : 12 lớp, 768-hidden, 12-chú ý, 110M tham số
BERT-Large, Uncasing : 24 lớp, 1024 ẩn, 16 chú ý, các tham số 340M
BERT-Base, Vỏ : 12 lớp, 768 ẩn, 12 đầu chú ý, tham số 110M
BERT-Large, Vỏ : 24 lớp, ẩn 1024, 16 đầu chú ý, tham số 340M
Chúng ta cần chọn phiên bản BERT được đào tạo trước dựa trên tình huống của chúng ta. Ví dụ: nếu chúng tôi không thể sử dụng Google TPU, tốt hơn chúng tôi nên chọn sử dụng kiểu cơ bản. Đối với việc lựa chọn "vỏ bọc" và "không theo dõi", nó phụ thuộc vào trường hợp các chữ cái có ảnh hưởng đến nhiệm vụ của chúng ta hay không. Tải xuống hướng dẫn này sử dụng mô hình BERT-Base-Cased.
2. Chuẩn bị dữ liệu
Để sử dụng BERT, chúng tôi cần chuyển đổi dữ liệu sang định dạng được sử dụng bởi BERT - chúng tôi có các tệp đánh giá định dạng csv. BERT có các yêu cầu đặc biệt đối với dữ liệu. Nó yêu cầu dữ liệu phải được lưu trong tệp tsv theo định dạng cụ thể được hiển thị bên dưới (bốn cột , Không có dòng tiêu đề):
- Cột 0: ID hàng
- Cột 1: Nhãn hàng (cần phải có kiểu int, chẳng hạn như 0, 1, 2, 3, v.v.)
- Cột 2: Trong cột này, tất cả các hàng có cùng một chữ cái - đây là cột dư thừa hơn mà chúng ta cần đưa vào, nhưng BERT cần nó.
- Cột 3: Văn bản ví dụ chúng tôi muốn phân loại
Tạo một thư mục trong thư mục mà bạn đã nhân bản BERT để thêm ba tệp riêng biệt vào đó: train.tsv, dev.tsv, test.tsv (tsv là một giá trị được phân tách bằng tab). Tất cả 4 cột được bao gồm trong train.tsv và dev.tsv. Trong test.tsv, chúng ta chỉ cần giữ 2 cột, id được sử dụng để xác định hàng và văn bản sẽ được phân loại.
Đoạn mã sau trình bày cách chúng tôi đọc các nhận xét của Yelp và đặt BERT một cách thích hợp. Để biết chi tiết, hãy xem: http://gist.github.com/samk3211/1d233b29ce5acc93f4a3e8c13db8ccd3
3. Đào tạo với mô hình BERT được đào tạo trước
Trước khi tiếp tục, hãy xác nhận rằng những điều sau đây đã sẵn sàng:
- Tất cả các tệp .tsv phải được đặt trong thư mục dữ liệu trong thư mục BERT.
- Tạo một thư mục có tên "bertDefput" trong đó mô hình được điều chỉnh sẽ được lưu.
- Các mô hình BERT được đào tạo trước tồn tại trong thư mục BERT.
- Đường dẫn trong lệnh là đường dẫn tương đối "./"
Sau khi xác nhận, bạn có thể vào thư mục mà bạn đã nhân bản BERT và nhập lệnh sau:
Code Mã bản sao
Nếu chúng ta nhìn vào đầu ra trên thiết bị đầu cuối, chúng ta có thể thấy chuyển đổi văn bản đầu vào với các thẻ phụ, mà chúng ta đã biết khi thảo luận về các thẻ đầu vào khác nhau mà BERT mong đợi:
Đào tạo với BERT có thể gây ra lỗi tràn bộ nhớ. Điều này cho thấy rằng bạn cần các khả năng phần cứng mạnh mẽ hơn - GPU, RAM nhiều hơn và thậm chí cả TPU. Tuy nhiên, chúng ta có thể thử một số cách giải quyết và sau đó xem xét nâng cấp phần cứng. Ví dụ: chúng ta có thể cố gắng giảm training_batch_size; mặc dù điều này sẽ khiến việc đào tạo chậm hơn, không có bữa ăn trưa miễn phí trên thế giới và nó có thể được chấp nhận.
Đào tạo có thể mất một thời gian dài. Vì vậy, sau khi bạn chạy lệnh, bạn có thể đặt nó sang một bên, trừ khi máy của bạn rất mạnh. Tất nhiên, bạn không thể sử dụng máy tính của mình để làm những việc khác trong quá trình đào tạo - ít nhất tôi không thể làm việc tốt với máy tính trong quá trình đào tạo.
Chúng ta có thể thấy nhật ký tiến độ trên thiết bị đầu cuối. Sau khi đào tạo hoàn tất, chúng tôi sẽ nhận được báo cáo về hiệu suất của mô hình trong thư mục bertDefput; test_results.tsv được tạo trong thư mục đầu ra dựa trên dự đoán của tập dữ liệu thử nghiệm, chứa các giá trị xác suất dự đoán của nhãn lớp.
4. Đưa ra dự đoán về dữ liệu mới
Nếu chúng tôi muốn đưa ra dự đoán về dữ liệu thử nghiệm mới test.tsv, sau khi hoàn thành đào tạo mô hình, chúng tôi có thể nhập thư mục bertDefput và tập trung vào tệp model.ckpt với giá trị số cao nhất. Các tệp điểm kiểm tra này chứa trọng lượng của các mô hình được đào tạo. Khi chúng tôi có số điểm kiểm tra cao nhất, chúng tôi có thể chạy lại run_groupifier.py, nhưng lần này init_checkpoint nên được đặt thành điểm kiểm tra mô hình cao nhất, như được hiển thị bên dưới:
Code Mã bản sao
Điều này sẽ tạo ra một tệp có tên test_results.tsv với số lượng cột bằng số lượng thẻ lớp.
Lưu ý rằng chúng tôi đã đặt -do_predict = true trong giai đoạn đào tạo. Trong thực tế, cài đặt tham số này có thể được bỏ qua và kết quả kiểm tra có thể được tạo riêng bằng cách sử dụng lệnh trên. )
5. Phát triển kiến thức
Ở trên, chúng tôi đã sử dụng giải pháp vượt trội để đào tạo. Tuy nhiên, chúng tôi cũng có thể tùy chỉnh tinh chỉnh bằng cách tạo một lớp mới riêng biệt được đào tạo để điều chỉnh BERT cho nhiệm vụ phân loại tình cảm của chúng tôi (hoặc bất kỳ tác vụ nào khác). Nhưng bài đăng trên blog này đã rất dài, vì vậy tôi không có kế hoạch mở rộng nội dung của lớp tùy chỉnh trong bài viết này, nhưng tôi có thể cung cấp hai tài liệu tham khảo:
- Dưới đây là hướng dẫn được triển khai trong PyTorch, cũng dựa trên bộ dữ liệu người dùng Yelp tương tự.
- Các nhà nghiên cứu của Google đã tạo ra một máy tính xách tay colab tuyệt vời , trong đó chỉ ra chi tiết cách dự đoán xem đánh giá phim của IMDB sẽ là tích cực hay tiêu cực. Trường hợp này dựa trên mô hình BERT được đào tạo trước trong Tensorflow. Lớp mới.
Tóm tắt
BERT là một mô hình ngôn ngữ rất mạnh mẽ. Đây là một cột mốc quan trọng trong lĩnh vực NLP - nó cải thiện đáng kể khả năng chuyển giao việc học của chúng tôi trong NLP, nó có thể cung cấp giải pháp cho nhiều nhiệm vụ NLP khác nhau. Trong bài viết này, tôi cố gắng viết một hướng dẫn bắt đầu BERT hoàn chỉnh cho bạn, tôi hy vọng bạn có thể tìm hiểu một số nét đẹp của NLP từ nó.
Nếu bạn muốn tìm hiểu thêm về BERT, tôi khuyên bạn nên tham khảo bài viết gốc và repo Github mã nguồn mở có liên quan . Tất nhiên , cũng có một triển khai BERT trong PyTorch để bạn học hỏi.
Liên kết gốc:
Comments
Post a Comment